Send Data to BigQuery
-
Log in to BigQuery. To do so, log in to GCP (Google Cloud Platform) with your Google account.
-
Once connected to BigQuery, create a new project or use an existing one.
We can now start using BigQuery and its numerous functionalities. -
Create a service account. Navigate to .
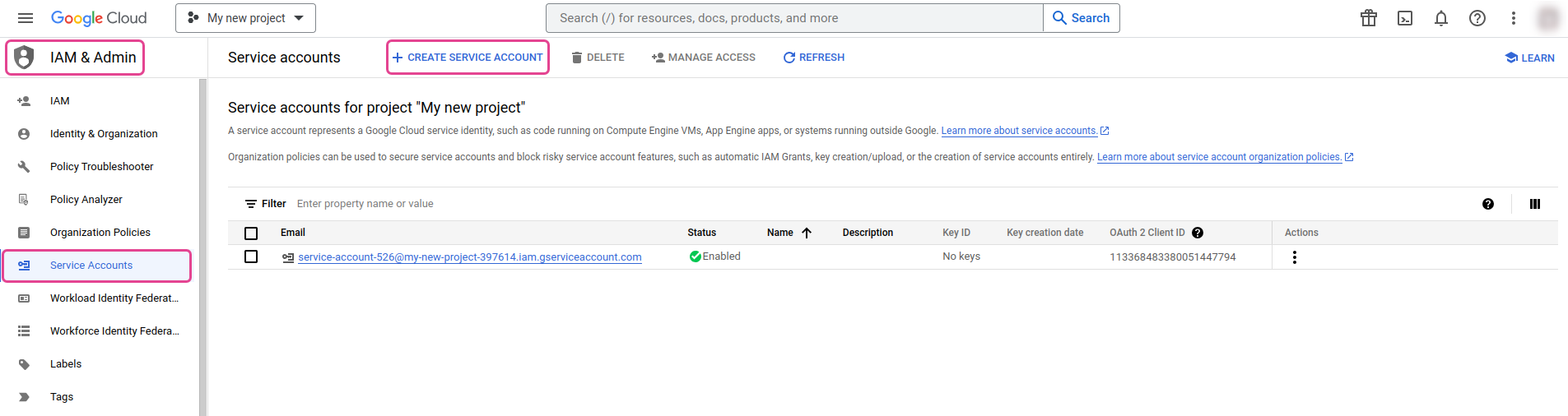
A page opens.
-
Fill in the required information and follow the steps that appear in the Google Cloud console.
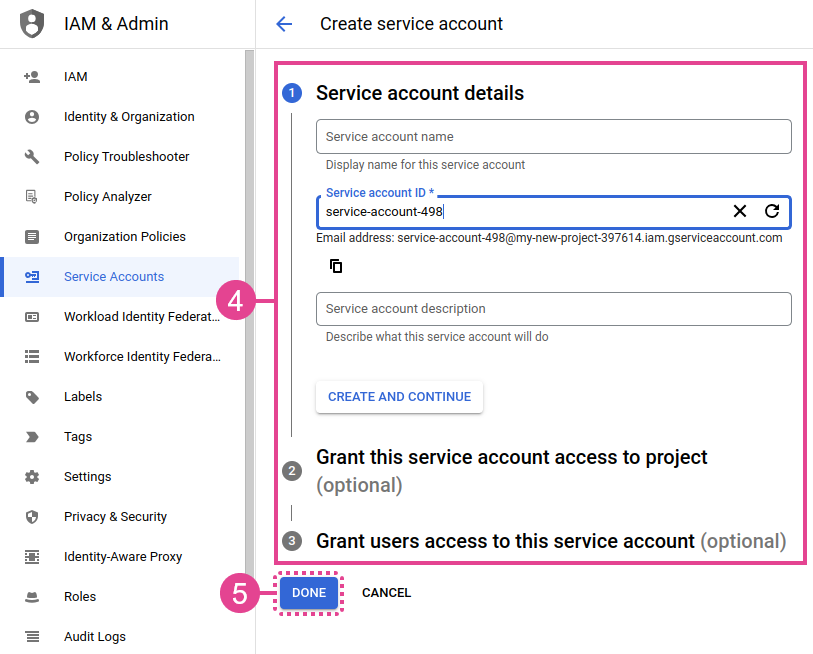
-
Click DONE to validate your service account creation.
Your service account appears in the service account list of your project. -
From the Actions column of the service account you created, click the kebab menu
 Manage keys to create your service account key.
Manage keys to create your service account key.
A page opens. -
Click .
A pop-up window opens. -
Select JSON for the Key type.
-
Click CREATE.
This will generate and download the JSON file containing your service account key. Keep this key carefully, as you will need it in your Saagie job to authenticate yourself in BigQuery. -
Create the files needed to run your job:
This is the
.jsonfile generated in step 9, which contains your service account key. The JSON key is required for authentication.The
requirements.txtfile contains a list of all the Python libraries to be installed, as well as their versions. This file is needed to import the various Python packages that are used in our job, such as the BigQuery client API, Pandas, etc. It is as follows:requirement.txtpandas==2.0.3 protobuf==4.24.3 google-api-core==2.11.1 google-auth==2.21.0 google-cloud-bigquery==3.11.3 google-cloud-core==2.3.3 google-crc32c==1.5.0 google-resumable-media==2.5.0 googleapis-common-protos==1.59.1 datasets==2.14.5
__main__.pyfrom google.cloud import bigquery from google.oauth2 import service_account import argparse import logging import pandas as pd from datasets import load_dataset import os parser = argparse.ArgumentParser(description='Send IMDB dataset from HuggingFace to BigQuery.') (1) parser.add_argument("--json_path", type=str, help="Path to the json authentication file", required=True) (1) parser.add_argument("--project_id", type=str, help='Big Query project ID', required=True) (1) args = parser.parse_args() (1) logger_info = logging.getLogger().setLevel(logging.INFO) def set_credentials(json_path, project_id): (2) credentials = service_account.Credentials.from_service_account_file(json_path) client = bigquery.Client(credentials= credentials, project=project_id) return client def load_dataset_from_hugging_face(): (3) datasets = load_dataset("imdb") train_imdb = datasets["train"].to_pandas() return train_imdb def load_local(client, project_id): (4) df = load_dataset_from_hugging_face() df = df.sample(frac=1, random_state=66).reset_index(drop=True) database_path = "IMDB_dataset.IMDB" job = client.load_table_from_dataframe(df, f"{project_id}.{database_path}") if not os.path.exists("/workdir/"): os.makedirs("/workdir/") with open("/workdir/output-vars.properties", "w") as f: # Writing data to a file f.write(f"DATABASE={database_path}") return job client = set_credentials(args.json_path, args.project_id) (5) result = load_local(client, args.project_id) (6) logging.info("DATASET LOADED INTO BIGQUERY") (7)Where:
1 This is the parser used to retrieve the arguments that are given as parameters to the job. 2 The set_credentialsfunction is to log in to BigQuery via the Python client API using the JSON key and the project identifier,project_id. This authentication ensures a secure connection to BigQuery. Once logged in, you can send queries to BigQuery et start working with your data.3 The load_dataset_from_hugging_facefunction loads IMDB data via HuggingFace dataset library, and converts it to a Pandas dataframe.4 The load_localfunction sends the data to your BigQuery project. It also adds the data location to a pipeline environment variable, which is automatically created in Saagie from our code. This information will be required in our next job.5 This line creates the client with the information retrieved from our set_credentialsfunction.6 This line uses the created client to authenticate to BigQuery. Then, it uses our load_localfunction to send the data to your BigQuery project.7 The code of your job ends with a log message to check that all went well. -
Zip these three files into a
.ziparchive. -
Now, in Saagie, create a new project or use an existing one.
If you use an existing project, make sure that the Python job technology from the official Saagie repository is enabled in your project. You can verify this in the Job Technologies tab of your project settings. -
Create a project environment variable
PROJECT_IDthat contains the name of your BigQuery project. It will be used when creating your job.Each job of our pipeline must contain the authentication code using the JSON key, and the project_idof the BigQuery project. This is why we store theproject_idin an environment variable, so that it is accessible to other jobs. -
-
Keep the default runtime context.
-
Add the zipped file created in step 11, which includes the
.json,__main__.py, andrequirement.txtfiles. -
Enter the command to run your Python code as follows:
python __main__.py --json_path ./my-new-project-397614.json --project_id $project_idWhere:
-
my-new-project-397614.jsonmust be replaced with the name of your JSON file. -
__main__.pycan be replaced by the name of your Python code file, if different. -
The
$project_idargument is to retrieve the value of thePROJECT_IDproject environment variable created earlier.
-
-
-
Once created, click Run
 to launch your job.
to launch your job.
In the next article, we will take a closer look at the IMDB data pre-processing stage. Stay tuned!