Use Talend on HDFS With High Availability
To follow this procedure, you must have a Repository containing the information of the Saagie platform. To this end, create a context group and define the contexts and variables required.
In this case, define the following context variables:
| Name | Type | Value | ||||
|---|---|---|---|---|---|---|
|
String |
|
Once your context group is created and stored in the Repository, you can apply the Repository context variables to your jobs.
| For more information, read the whole section on Using contexts and variables on Talend Studio User Guide. |
-
Create a new job in Talend.
-
Add the following components:
-
tHDFSConnection, to establish an HDFS connection reusable by other HDFS components. -
tHDFSList, to retrieve a list of files or folders in a local directory. -
tJava, to extend the functionalities of a Talend job using custom Java commands. (Print path file.)
-
-
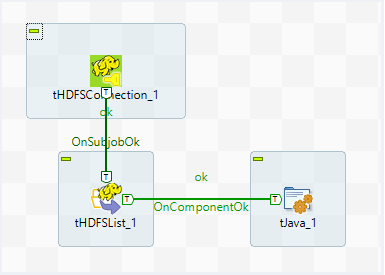
Link these components as follows:
-
Link
tHDFSConnectionandtHDFSListwith theOnSubjobOkconnection. -
Link
tHDFSListandtJavawith theOnComponentOkconnection.
-
-
Double-click each component and configure their settings as follows:
In the Basic settings tab:
-
From the Property type list, select Built-in so that no property data is stored centrally.
-
From the Distribution list, select the Cloudera cluster.
-
From the Version list, select the latest version of Cloudera.
-
In the NameNode URI field, enter the URI of the Hadoop NameNode, the master node of a Hadoop system:
context.HDFS_URI. -
In the Username field, enter the HDFS user authentication name.
-
Enter the following Hadoop properties:
Property Value "dfs.nameservices""nameservice1""dfs.ha.namenodes.cluster""nn1,nn2""dfs.client.failover.proxy.provider.cluster""org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider""dfs.namenode.rpc-address.cluster.nn1""nn1.p1.saagie.prod.saagie.io:8020""dfs.namenode.rpc-address.cluster.nn2""nn2.p1.saagie.prod.saagie.io:8020"How to retrieve the names of nn1 and nn2?To determine the names of nn1 and nn2 for
dfs.namenode.rpc-address.cluster.nn1anddfs.namenode.rpc-address.cluster.nn2, do the following:-
Create a Bash job in Saagie, with the following line of code:
cat /etc/hadoop/conf/hdfs-site.xml. -
Run the job.
-
Retrieve the result from the job’s instance logs.
-
For more information, you can refer to Talend’s documentation on the tHDFSConnectioncomponent.In the Basic settings tab:
-
From the Property type list, select Built-in so that no property data is stored centrally.
-
Select the Use an existing connection option.
-
From the Component List list, select the connection component
tHDFSConnectionto reuse the connection details already defined. -
In the HDFS directory field, browse to, or enter the path pointing to the data to be used in the file system.
-
From the FileList Type list, select the type of input you want to iterate on from the list.
-
Select the Use Glob Expressions as Filemask option.
-
In the Files field, add as many File mask as required.
For more information, you can refer to Talend’s documentation on the tHDFSListcomponent.For more information, you can refer to Talend’s documentation on the tJavacomponent. -
-
Run the job.
-
HDFS with high availability in Talend (GitHub page)