Read and Write Tables From Hive With Talend
Without Kerberos
To follow this procedure, you must have a Repository containing the information of the Saagie platform. To this end, create a context group and define the contexts and variables required.
In this case, define the following context variables:
| Name | Type | Value |
|---|---|---|
|
String |
Your Hive IP address |
|
String |
Your Hive port |
|
String |
The Hive source table |
|
String |
The Hive working database |
|
String |
The Hive user authentication name |
|
String |
The Hive target table |
|
Password |
The Hive user account password |
Once your context group is created and stored in the Repository, you can apply the Repository context variables to your jobs.
| For more information, read the whole section on Using contexts and variables on Talend Studio User Guide. |
Read Tables
-
Create a new job in Talend.
-
Add the following components:
-
tHiveConnection, to establish a connection to a Hive database to be reused by other Hive components in your job. -
tHiveInput, to extract data from Hive and send the data to the following component. -
tLogRow, to display the result.
-
-
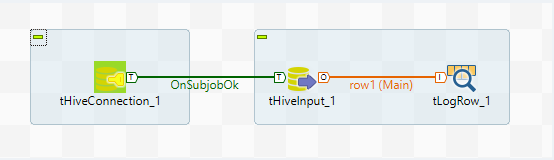
Link these components as follows:
-
Link
tHiveConnectionandtHiveInputwith theOnSubjobOkconnection. -
Link
tHiveInputandtLogRowwith theMainconnection.
-
-
Double-click each component and configure their settings as follows:
In the Basic settings tab:
-
From the Property type list, select Built-in so that no property data is stored centrally.
-
From the Distribution list, select the Cloudera cluster.
-
From the Version list, select the latest version of Cloudera.
-
From the Connection mode list, select a connection mode.
-
From the Hive server list, select the Hive server through which you want the job using this component to execute queries on Hive.
-
In the Host field, enter the database server IP address.
-
In the Port field, enter the listening port number of the database server.
-
In the Database field, enter the name of the database.
-
In the Username and Password fields, enter the authentication information of the user.
-
In the Additional JDBC Settings field, you can specify additional connection properties for the database connection you are creating.
For more information, you can refer to Talend’s documentation on the tHiveConnectioncomponent.In the Basic settings tab:
-
From the Property type list, select Built-in so that no property data is stored centrally.
-
Select the Use an existing connection option.
-
From the Component List list, select the connection component
tHiveConnectionto reuse the connection details already defined. -
From the Schema list, select Built-In to create and store the schema locally for this component only.
-
In the Table name field, enter the name of the table.
-
From the Query type field, select Built-In to fill in manually the query statement or build it graphically using SQLBuilder.
-
In the Query field, enter your database query as follows:
"SELECT COUNT(*) FROM "+context.Table_Hive+"".
For more information, you can refer to Talend’s documentation on the tHiveInputcomponent.For more information, you can refer to Talend’s documentation on the tLogRowcomponent. -
-
Run the job.
Write Tables
-
Create a new job in Talend.
-
Add the following components:
-
tHiveConnection, to establish a connection to a Hive database to be reused by other Hive components in your job. -
tHiveRow, to execute a SQL query at each iteration of the Talend flow.
-
-
Link these components with the
OnSubjobOkconnection.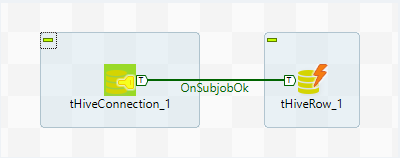
-
Double-click each component and configure their settings as follows:
In the Basic settings tab:
-
From the Property type list, select Built-in so that no property data is stored centrally.
-
From the Distribution list, select the Cloudera cluster.
-
From the Version list, select the latest version of Cloudera.
-
From the Connection mode list, select a connection mode.
-
From the Hive server list, select the Hive server through which you want the job using this component to execute queries on Hive.
-
In the Host field, enter the database server IP address.
-
In the Port field, enter the listening port number of the database server.
-
In the Database field, enter the name of the database.
-
In the Username and Password fields, enter the authentication information of the user.
-
In the Additional JDBC Settings field, you can specify additional connection properties for the database connection you are creating.
For more information, you can refer to Talend’s documentation on the tHiveConnectioncomponent.In the Basic settings tab:
-
From the Property type list, select Built-in so that no property data is stored centrally.
-
Select the Use an existing connection option.
-
From the Component List list, select the connection component
tHiveConnectionto reuse the connection details already defined. -
From the Schema list, select Built-In to create and store the schema locally for this component only.
-
In the Table name field, enter the name of the table.
-
From the Query type field, select Built-In to fill in manually the query statement or build it graphically using SQLBuilder.
-
In the Query field, enter your database query as follows:
"CREATE TABLE "+context.New_Table_Hive+" AS SELECT * FROM "+context.Table_Hive+" LIMIT 10".
For more information, you can refer to Talend’s documentation on the tHiveRowcomponent. -
-
Run the job.
With Kerberos
To follow this procedure, you must have a Repository containing the information of the Saagie platform. To this end, create a context group and define the contexts and variables required.
In this case, define the following context variables:
| Name | Type | Value |
|---|---|---|
|
String |
The Kerberos user authentication name |
|
String |
The Kerberos user account password |
|
String |
The Kerberos principal name |
|
String |
The kerberos principal for Hive service |
|
String |
Your Hive IP address |
|
int | Integer |
Your Hive port |
|
String |
URI to store file in HDFS |
Once your context group is created and stored in the Repository, you can apply the Repository context variables to your jobs.
| For more information, read the whole section on Using contexts and variables on Talend Studio User Guide. |
Read Tables With a Kerberized Cluster
-
Create a new job in Talend.
-
Add the following components:
-
tSystem, to establish the Kerberos connection. -
tHiveConnection, to establish a connection to a Hive database to be reused by other Hive components in your job. -
tHiveInput, to extract data from Hive and send the data to the following component. -
tLogRow, to display the result.
-
-
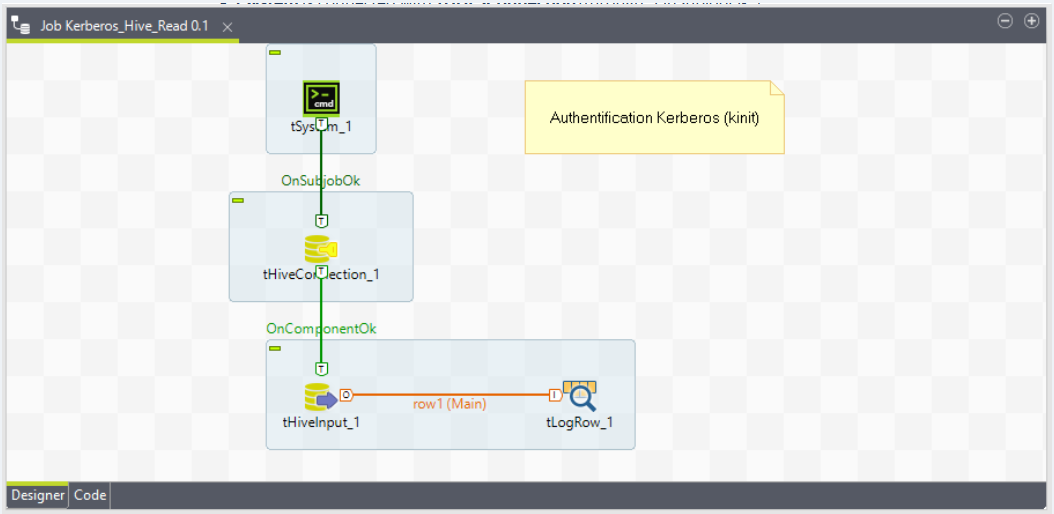
Link these components as follows:
-
Link
tSystemandtHiveConnectionwith theOnSubjobOkconnection. -
Link
tHiveConnectionandtHiveInputwith theOnComponentOkconnection. -
Link
tHiveInputandtLogRowwith theMainconnection.
-
-
Double-click each component and configure their settings as follows:
In the Basic settings tab:
-
Select the Use Array Command option.
It will activate its Command field. -
In this Command field, enter the following system command in array, one parameter per line.
"/bin/bash" "-c" "echo '"+context.kerberos_pwd+"' | kinit "+context.kerberos_login
-
From the Standard Output and Error Output list, select the type of output for the processed data to be transferred to.
-
From the Schema list, select Built-In to create and store the schema locally for this component only.
For more information, you can refer to Talend’s documentation on the tSystemcomponent.In the Basic settings tab:
-
From the Property type list, select Built-in so that no property data is stored centrally.
-
From the Distribution list, select the Cloudera cluster.
-
From the Version list, select the latest version of Cloudera.
-
From the Connection mode list, select a connection mode.
-
From the Hive server list, select the Hive server through which you want the job using this component to execute queries on Hive.
-
In the Host field, enter the database server IP address.
-
In the Port field, enter the listening port number of the database server.
-
In the Database field, enter the name of the database.
-
In the Username and Password fields, enter the authentication information of the user.
-
In the Additional JDBC Settings field, you can specify additional connection properties for the database connection you are creating.
-
Select the Use kerberos authentication option, and then enter the relevant parameters in the fields that appear.
For more information, you can refer to Talend’s documentation on the tHiveConnectioncomponent.In the Basic settings tab:
-
From the Property type list, select Built-in so that no property data is stored centrally.
-
Select the Use an existing connection option.
-
From the Component List list, select the connection component
tHiveConnectionto reuse the connection details already defined. -
From the Schema list, select Built-In to create and store the schema locally for this component only.
-
In the Table name field, enter the name of the table.
-
From the Query type field, select Built-In to fill in manually the query statement or build it graphically using SQLBuilder.
-
In the Query field, enter your database query.
For more information, you can refer to Talend’s documentation on the tHiveInputcomponent.For more information, you can refer to Talend’s documentation on the tLogRowcomponent. -
-
Run the job.
Write Tables With a Kerberized Cluster
-
Create a new job in Talend.
-
Add the following components:
-
tSystem, to establish a Kerberos connection. -
tHiveConnection, to establish a connection to a Hive database to be reused by other Hive components in your job. -
tHDFSConnection, to establish an HDFS connection. -
tHiveCreateTable, to create Hive tables that fit a wide range of Hive data formats. -
tRowGenerator, to generate data. -
tHDFSOutput, to write data flows it receives into a given HDFS. -
tHiveLoad, to write data of different formats into a given Hive table or to export data from a Hive table to a directory.
-
-
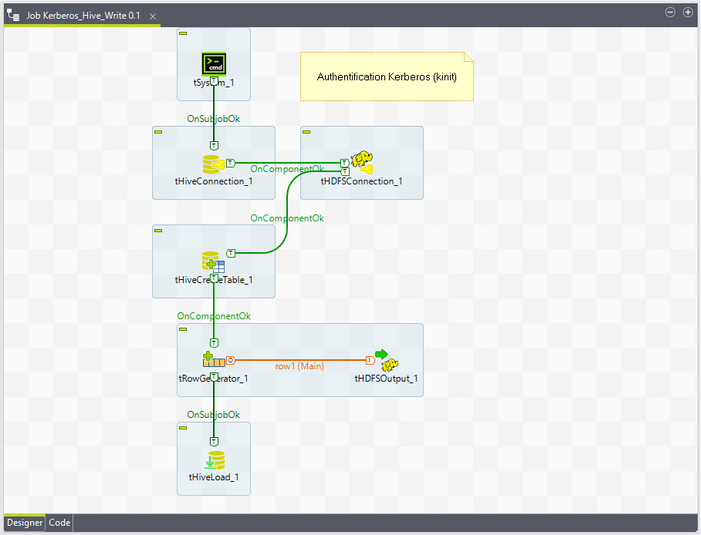
Link these components as follows:
-
Link
tSystemandtHiveConnectionwith theOnSubjobOkconnection. -
Link
tHiveConnectionandtHDFSConnectionwith theOnComponentOkconnection. -
Link
tHDFSConnectionandtHiveCreateTablewith theOnComponentOkconnection. -
Link
tHiveCreateTableandtRowGeneratorwith theOnComponentOkconnection. -
Link
tRowGeneratorandtHDFSOutputwith theMainconnection. -
Link
tHDFSOutputandtHiveLoadwith theOnSubjobOkconnection.
-
-
Double-click each component and configure their settings as follows:
In the Basic settings tab:
-
Select the Use Array Command option.
It will activate its Command field. -
In this Command field, enter the following system command in array, one parameter per line.
"/bin/bash" "-c" "echo '"+context.kerberos_pwd+"' | kinit "+context.kerberos_login
-
From the Standard Output and Error Output list, select the type of output for the processed data to be transferred to.
-
From the Schema list, select Built-In to create and store the schema locally for this component only.
For more information, you can refer to Talend’s documentation on the tSystemcomponent.In the Basic settings tab:
-
From the Property type list, select Built-in so that no property data is stored centrally.
-
From the Distribution list, select the Cloudera cluster.
-
From the Version list, select the latest version of Cloudera.
-
From the Connection mode list, select a connection mode.
-
From the Hive server list, select the Hive server through which you want the job using this component to execute queries on Hive.
-
In the Host field, enter the database server IP address.
-
In the Port field, enter the listening port number of the database server.
-
In the Database field, enter the name of the database.
-
In the Username and Password fields, enter the authentication information of the user.
-
In the Additional JDBC Settings field, you can specify additional connection properties for the database connection you are creating.
-
Select the Use kerberos authentication option, and then enter the relevant parameters in the fields that appear.
For more information, you can refer to Talend’s documentation on the tHiveConnectioncomponent.In the Basic settings tab:
-
From the Property type list, select Built-in so that no property data is stored centrally.
-
From the Distribution list, select the Cloudera cluster.
-
From the Version list, select the latest version of Cloudera.
-
In the NameNode URI field, enter the URI of the Hadoop NameNode, the master node of a Hadoop system.
-
Select the Use kerberos authentication option, and then enter the relevant parameters in the fields that appear.
For more information, you can refer to Talend’s documentation on the tHDFSConnectioncomponent.In the Basic settings tab:
-
From the Property type list, select Built-in so that no property data is stored centrally.
-
Select the Use an existing connection option.
-
From the Component List list, select the connection component
tHiveConnectionto reuse the connection details already defined. -
From the Schema list, select Built-In to create and store the schema locally for this component only.
-
In the Table name field, enter the name of the table.
-
From the Action on table list, select the action to be carried out for creating a table.
-
From the Format list, select the data format to which the table to be created is dedicated.
-
Select the Set Delimited row format option.
For more information, you can refer to Talend’s documentation on the tHiveCreateTablecomponent.For more information, you can refer to Talend’s documentation on the tRowGeneratorcomponent.In the Basic settings tab:
-
From the Property type list, select Built-in so that no property data is stored centrally.
-
From the Schema list, select Built-In to create and store the schema locally for this component only.
-
Select the Use an existing connection option.
-
From the Component List list, select the connection component
tHiveConnectionto reuse the connection details already defined. -
From the Load action list, select the type of the file to be processed.
-
From the Action list, select the action that you want to perform on the file.
-
In the Row separator field, identify the end of a row.
-
In the Field separator field, enter a character, a string, or a regular expression to separate fields for the transferred data.
For more information, you can refer to Talend’s documentation on the tHDFSOutputcomponent.In the Basic settings tab:
-
From the Property type list, select Built-in so that no property data is stored centrally.
-
Select the Use an existing connection option.
-
From the Component List list, select the connection component
tHDFSConnectionto reuse the connection details already defined. -
From the Load action list, select the action you need to carry for writing data into the specified destination.
-
In the File path field, enter the directory you need to read data from or write data in, depending on the action you have selected from the Load action list.
-
In the Table name field, enter the name of the Hive table you need to write data in.
-
From the Action on file list, select the action to be carried out for writing data.
For more information, you can refer to Talend’s documentation on the tHiveLoadcomponent. -
-
Run the job.